

Share this post
At two clusters, Kubernetes feels manageable. At twenty, spread across multiple cloud providers, on-premises racks, and edge locations, the operational model that got you here starts working against you.
Policies that should be identical across environments quietly diverge. Upgrades that should take hours stretch into days because no two clusters follow the same lifecycle workflow. Your platform engineers, who should be focused on building, spend most of their week logging into different dashboards trying to understand why one cluster is behaving differently from the rest.
Kubernetes fleet management turns fragmented cluster sprawl into a single, governed, consistent, and observable infrastructure system.
This guide covers what Kubernetes fleet management means, how it differs from standard multi-cluster management, the core components that hold a fleet together, and the steps you can take right now to run a growing fleet without the chaos that usually comes with it.
What Is Kubernetes Fleet Management?
Kubernetes fleet management is the centralized administration of multiple Kubernetes clusters, treating them as a single group rather than individual units. In other words, it’s the practice of treating every cluster across your environments, regions, and cloud providers as part of one unified operational domain you control from a single point of control.
At its core, it covers four responsibilities:
- Workload distribution across clusters
- Policy and governance enforcement at scale
- Lifecycle management covering upgrades, patches, and provisioning
- Visibility into cluster health and configuration drift
Without a fleet-level approach, you end up manually applying the same configurations across dozens or hundreds of clusters, creating inconsistencies and multiplying operational risk with every new cluster you add.
Kubernetes Fleet vs Multi-Cluster Management
These two terms get used interchangeably, but they describe different levels of operational maturity. Here’s how they actually differ:
Multi-cluster management allows you to run workloads across multiple clusters. Fleet management gives you the operational control to govern, update, and observe all of them as a single system.
Think of multi-cluster management as having five servers, each configured manually by a different engineer. Fleet management is what happens when you replace that with a single pipeline that enforces the same state across all five, every time, without exception.
Core Components of Kubernetes Fleet Management
Here are the key components of Kubernetes fleet management.
Cluster Lifecycle Management
Every cluster in your fleet has a lifecycle. It gets provisioned, upgraded, patched, and eventually decommissioned. Without a fleet-level approach, you handle each of those events manually per cluster, which limits scaling beyond a handful of environments.
Lifecycle management at the fleet level means provisioning new clusters from a standardized template, rolling out upgrades across all clusters on a coordinated schedule, and retiring clusters without leaving any orphaned workloads behind.
That means no cluster in your fleet runs a Kubernetes version or configuration that the rest of the fleet has already moved past.
Policy and Governance Enforcement
Governance ensures every cluster in your fleet operates within the boundaries your organization defines, covering security policies, resource quotas, RBAC rules, and compliance requirements.
Without centralized governance, each cluster becomes a policy island. One engineer tightens RBAC in production. Another skips it in staging. Over time, your fleet accumulates inconsistencies that create security gaps and lead to audit failures.
Fleet-level governance enforces the same policies across every cluster from a single control point. When a policy changes, it propagates fleet-wide rather than requiring manual updates per environment.
Workload Distribution and Scheduling
At the fleet level, workload distribution determines which clusters run which workloads, and under what conditions traffic or compute shifts between them. Standard Kubernetes scheduling operates only within a single cluster, so fleet-level scheduling fills the gap left by native Kubernetes.
It allows you to place workloads based on cluster capacity, geographic proximity, cloud provider, or compliance requirements. When one cluster becomes unavailable or overloaded, workloads move to another without manual intervention.
Configuration Management and Drift Detection
Configuration drift is one of the most common failure points in multi-cluster environments. It happens when clusters that started identical gradually diverge due to manual changes, failed rollouts, or environment-specific patches applied without propagating to the rest of the fleet.
Fleet-level configuration management keeps every cluster aligned to a declared desired state, typically through GitOps workflows. When a cluster drifts from that state, the system detects it and flags it for remediation, or corrects it automatically depending on your policy.
Centralized Observability
Observability across a fleet means more than having metrics for each cluster. It means consolidating health data, logs, and performance signals from all clusters in one place so you can determine whether an issue is isolated to a single cluster or affects the entire fleet.
Without centralized observability, diagnosing a latency spike requires logging into each cluster individually and manually comparing dashboards.
With fleet-level observability, you see the full picture from a single view and can pinpoint the affected scope in minutes rather than hours.
That’s why many industry-leading enterprises use Portainer as their unified management plane, aggregating visibility, health monitoring, and performance metrics across multiple Kubernetes clusters in a single interface.
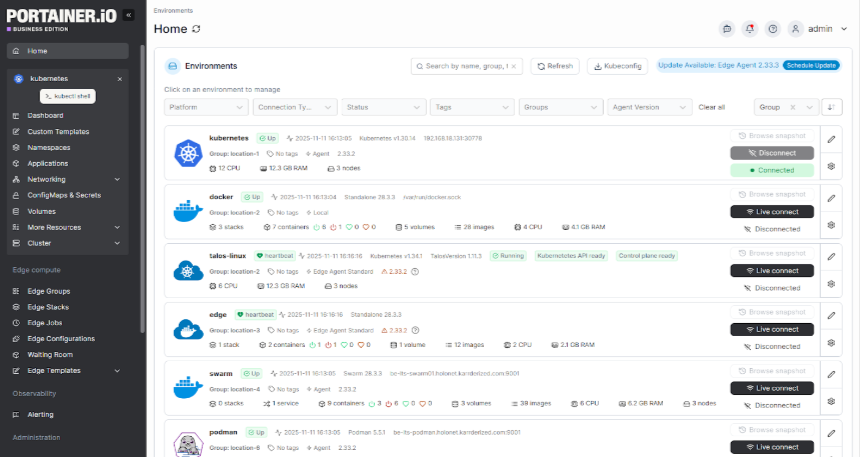
Explore Portainer’s Business Edition plan to get real-time visibility across your entire fleet and spend less time diagnosing, more time resolving.
{{article-cta}}
How to Optimize & Simplify Kubernetes Fleet Management
These are the steps organizations running their fleet efficiently implement to avoid configuration drift, failed upgrades, and visibility gaps:
Standardize Your Cluster Lifecycle Workflow Before You Scale
The biggest source of fleet complexity isn’t the number of clusters, but the different ways those clusters get provisioned, updated, and maintained. When each engineer brings their own workflow, the fleet fragments operationally, even when it appears unified on paper. That’s why you need to standardize your cluster lifecycle.
As one experienced Kubernetes engineer shared on Reddit:
“One of the best things for a small team to do is standardize on a workflow and lifecycle. For some people, that’s Terraform, others GitOps, Cluster API, or a specific product.”
Standardization means picking one provisioning approach and enforcing it across every cluster in your fleet, whether that’s Terraform modules, Cluster API, or a managed control plane model. The specific tool matters less than the consistency with which your entire fleet uses it.
Cluster API is worth highlighting here. By running control planes as pods within a management cluster, you flatten the infrastructure differences across providers such as EKS and AKS. Upgrades become a matter of starting a new ReplicaSet rather than touching each cluster individually.
Use Managed Kubernetes Services to Reduce Lifecycle Overhead
On-premises cluster management introduces a category of operational work that managed services handle for you, including node bootstrapping, certificate rotation, and version upgrades.
When you’re running a mixed fleet across multiple cloud providers and on-premises environments, the operational gap can be difficult to manage.
A Reddit SRE described from direct experience:
“Maintaining Terraform modules for each cloud provider, keeping clusters updated (fairly easy with managed services, but a nightmare for on-prem), rotating certificates; these were the pain points that led me to develop a different approach.”
Managed Kubernetes services handle the infrastructure coupling problem by owning the control plane on your behalf. If you’re managing mixed environments, the practical strategy is to use managed services wherever available and standardize the operational layer across both managed and unmanaged clusters rather than trying to manage each environment differently.
Portainer Kubernetes managed services pairs your team with experienced Kubernetes engineers who design, operate, and optimize your platform while you retain full visibility and self-serve control through the Portainer interface.
Contact our managed services team to build and manage your Kubernetes platform without operational risk.
Further reading: 7 Best Kubernetes Managed Services Providers
Automate Policy Enforcement and Stop Treating Compliance as a Manual Process
Most fleet governance failures happen because those organizations’ policies exist in documentation rather than in code. When policy enforcement depends on engineers remembering to apply the right RBAC rules, resource quotas, and security configurations to each new cluster, drift is inevitable.
The operational model that scales is one in which policies are declared once and automatically enforced across every cluster in your fleet. GitOps workflows handle this well: your desired state lives in a repository, and any cluster that drifts from it is automatically flagged or corrected without manual intervention.
Pro tip: Consolidating workloads into larger, shared clusters with strict RBAC enforced at the namespace level reduces the total number of policies you need to manage. Fewer clusters with proper access controls are operationally simpler than hundreds of single-application clusters, each of which requires its own governance layer.
Use Portainer to Unify Fleet Operations Across Every Environment
Each of the steps above solves a specific operational problem. Portainer connects all of them inside a single management plane, so you’re not switching between tools to provision clusters, enforce policies, and monitor fleet health.
Portainer gives you centralized control over Kubernetes clusters through a single interface, covering workload deployment, access control, configuration management, and real-time observability across your entire fleet.
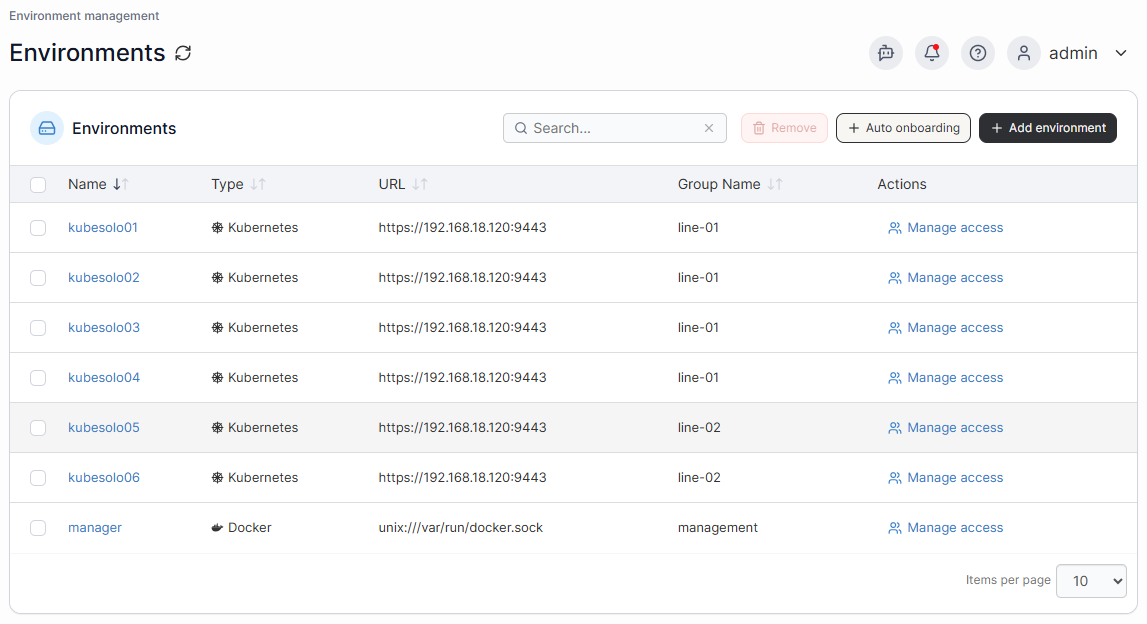
Its granular RBAC system also allows you to define exactly who can access what across every cluster in your fleet, down to the namespace level, so access control stays consistent without requiring manual configuration on each cluster individually.
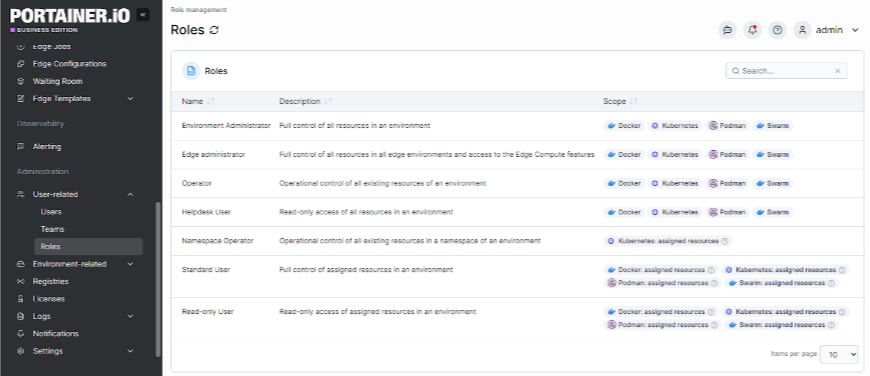
Rather than building a custom toolchain to cover each operational layer, Portainer provides a unified control plane that makes fleet-level decisions executable from a single place.
Portainer is also fully vendor-agnostic. Whether your fleet spans AWS EKS, Azure AKS, Google GKE, on-premises clusters, or a mix of all four, Portainer connects to all of them through a single interface without locking you into any one cloud provider’s toolchain or licensing model.
Book a demo to see how Portainer will simplify fleet operations across your entire infrastructure.
Empower Your Platform Engineers to Manage Your Kubernetes Fleet Without Any Complexity
Most platform engineering teams aren’t struggling because Kubernetes is hard but because every operational layer requires a different tool, a different dashboard, and another context switch at the worst possible time. That’s what drives burnout, not the technology itself.
Portainer replaces that fragmented stack with a single control plane that covers lifecycle management, governance, RBAC enforcement, and real-time observability across every Kubernetes cluster in your fleet.
As a result, your platform engineers will spend less time context-switching between tools and more time making decisions that actually move your infrastructure forward.
Choose Portainer’s Business Edition plan to consistently govern, secure, and operate your Kubernetes clusters without chaos.
FAQs on Kubernetes Fleet Management
- Is Kubernetes fleet management only relevant for large enterprises?
No. Any organization running more than two or three clusters benefits from a fleet management approach. Without it, operational complexity scales faster than your infrastructure does, regardless of company size.
- How does configuration drift affect a Kubernetes fleet?
Configuration drift occurs when clusters that started with identical configurations gradually diverge because of manual changes or environment-specific patches. If left unaddressed, it creates security gaps, compliance failures, and unpredictable workload behavior across your fleet.
- What should you look for in a Kubernetes fleet management tool?
Look for centralized policy enforcement, lifecycle automation, multi-cluster observability, and RBAC controls that operate at the fleet level. The right tool reduces the number of interfaces your platform engineers work across, not adds to them.


.png)
.png)